
Jun's Development Journey
[Java/문법] 스레드 -2 본문
1. 스레드 그룹
- 관련된 스레드를 묶어서 관리할 목적으로 이용된다.
- JVM이 실행되면 system 스레드 그룹을 만들고, JVM 운영에 필요한 스레드들을 생성해서 system 스레드 그룹에 포함시킨다. 그리고 system의 하위 스레드 그룹으로 main을 만들고, 메인 스레드를 main 스레드 그룹에 포함시킨다.
- 스레드는 반드시 하나의 스레드 그룹에 포함되는데, 명시적으로 스레드 그룹에 포함시키지 않으면 기본적으로 자신을 생성한 스레드와 같은 그룹에 속하게 된다.
- ex

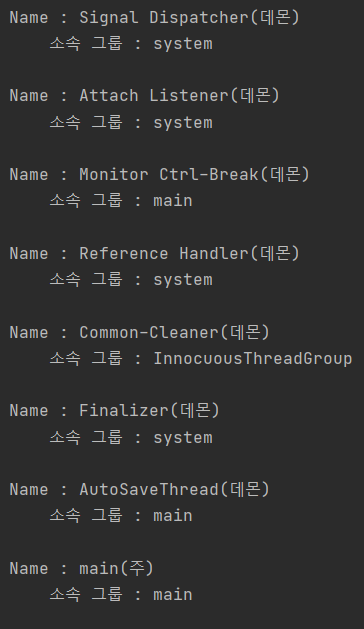
- Finalizer 스레드를 비롯한 일부 스레드들이 system 그룹에 속하고, main 스레드는 system 그룹의 하위 그룹인 main에 속해있다.
- main 스레드가 실행시킨 AutoSaveThread는 main 스레드가 소속된 main 그룹에 포함되어 있다.
2. 스레드 그룹 생성
2-1) 그룹 생성
1) ThreadGroup tg = new TheadGroup(String name);
2) ThreadGroup tg = new TheadGroup(ThreadGroup parent, String name);
2-2) 스레드 그룹 지정
- 새로운 스레드 그룹 생성 후 이 그룹에 스레드를 포함시키려면 Thread 객체를 생성할 때 생성자 매개값으로 스레드 그룹을 지정하면 된다.
1) Thread thread = new Thread(ThreadGroup group, Runnable target);
2) Thread thread = new Thread(ThreadGroup group, Runnable target, String name);
3) Thread thread = new Thread(ThreadGroup group, Runnable target, long stackSize);
=> long 타입의 stackSize는 JVM이 이 스레드에 할당할 stack 사이즈이다.
4) Thread thread = new Thread(ThreadGroup group, String name);
3. 스레드 그룹의 일괄 interrupt()
- 스레드 그룹에서 제공하는 interrupt() 메소드를 이용하면 그룹 내에 포함된 모든 스레드들을 일괄 interrupt 할 수 있다.
- 소속된 스레드의 interrupt() 메소드를 호출만 할 뿐 개별 스레드에서 발생하는 InterruptException에 대한 예외 처리를 하지 않는다. 안전한 종료를 위해선 개별 스레드가 예외 처리를 해야한다.
- ex



4. 스레드풀
- 병렬 작업 처리가 많아지면 스레드 개수가 증가되고, 그에 따른 스레드 생성과 스케쥴링으로 인해 CPU가 바빠져 메모리 사용량이 늘어난다. 따라서 애플리케이션의 성능이 저하된다.
- 갑작스런 병렬 작업의 폭증으로 인한 스레드 폭증을 막으려면 스레드풀을 사용해야 한다.
- 스레드풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해놓고 작업 큐에 들어오는 작업들을 하나씩 스레드가 맡아 처리한다. 작업 처리가 끝난 스레드는 다시 작업 큐에서 새로운 작업을 가져와 처리한다.
- 이러한 방식으로 인해 작업 처리 요청이 폭증되어도 스레드의 전체 개수가 늘어나지 않으므로 성능 저하가 적다.
4-1) 스레드풀 생성 및 종료
- execute 메소드 실행 예시

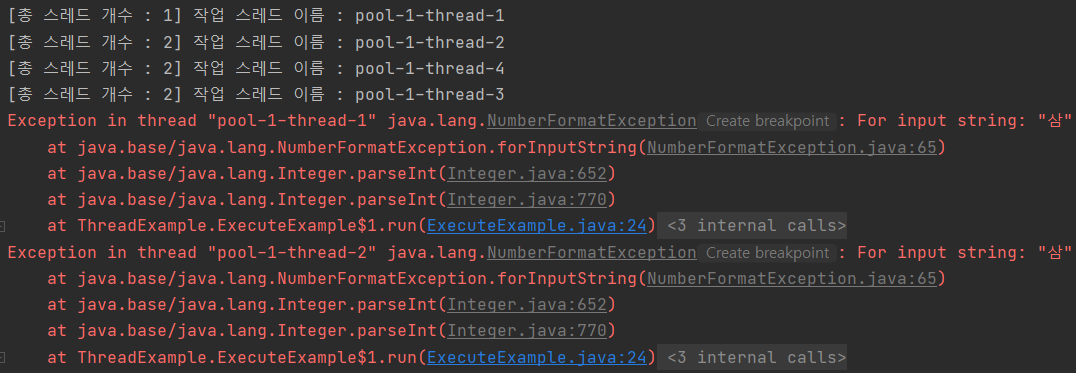

- 스레드풀의 스레드 최대 개수 2는 변함없지만, 실행 스레드의 이름을 보면 모두 다른 스레드가 작업을 처리하고 있다.
- 이는 작업 처리 도중 예외(NumberFormatException)가 발생했기 때문에 해당 스레드는 제거되고 새 스레드가 계속 생성되기 때문이다.
- submit 메소드 실행 예시
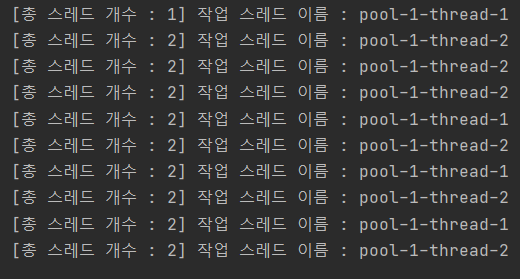
- execute와 달리 예외가 발생하더라도 스레드가 종료되지 않고 계속 재사용되어 다른 작업을 처리한다.
4-2) 블로킹 방식의 작업 완료 통보
- ExecutorService의 submit() 메소드는 매개값으로 준 Runnable 또는 Callable 작업을 스레드풀의 작업 큐에 저장하고 즉시 Future 객체를 리턴한다.
- Future의 get() 메소드를 호출하면 스레드가 작업을 완료할 때까지 블로킹되었다가 작업을 완료하면 처리 결과를 리턴한다. 이것이 블로킹을 사용하는 작업 완료 통보 방식이다.
- 주의할 점은 스레드가 작업을 완료하기 전까지는 get() 메소드가 블로킹되므로 다른 코드를 실행할 수 없다.
- 만약 UI를 변경하고 이벤트를 처리하는 스레드가 get() 메소드를 호출하면 작업을 완료하기 전까지 UI를 변경할 수도 없고 이벤트를 처리할 수도 없다. 그렇기 때문에 get() 메소드를 호출하는 스레드는 새로운 스레드이거나 스레드풀의 또 다른 스레드가 되어야 한다.
4-3) 리턴값이 없는 작업 완료 통보
- 리턴값이 없는 작업일 경우는 Runnable 객체로 생성하면 된다.
- 아래 예제는 리턴값이 없고 단순히 1부터 10까지 합을 출력하는 작업을 Runnable 객체로 생성하고, 스레드풀의 스레드가 처리하도록 요청한 것이다.


4-4) 리턴값이 있는 작업 완료 통보
- 스레드풀의 스레드가 작업을 완료한 후애 애플리케이션이 처리 결과를 얻어야 한다면 작업 객체를 Callable로 생성하면 된다.
- 주의할 점은 제네릭 타입 파라미터 T는 call() 메소드가 리턴하는 타입이 되도록 한다.

4-5) 작업 처리 결과를 외부 객체에 저장
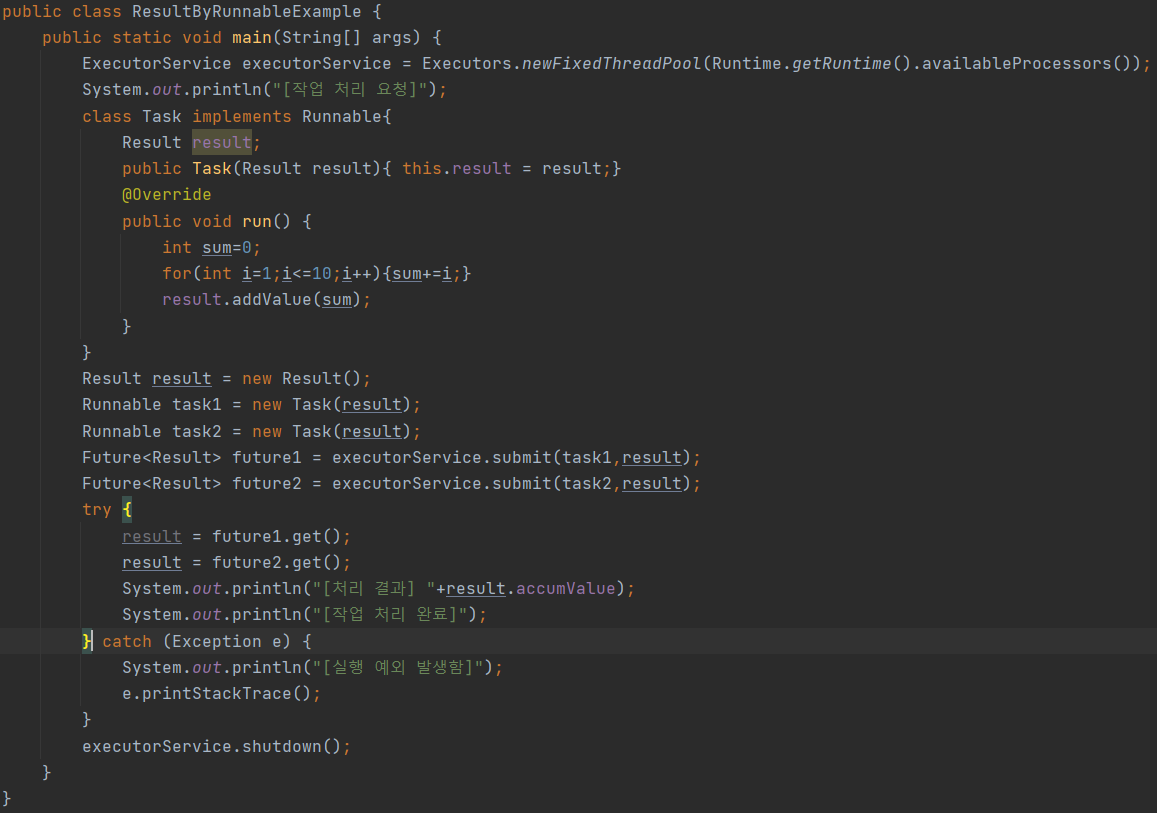
- 상황에 따라서 스레드가 작업한 결과를 외부 객체에 저장해야 하는 경우도 있다.
- 예를 들어 스레드가 작업 처리를 완료하고 외부 Result 객체에 작업 결과를 저장하면, 애플리케이션이 Result 객체를 사용해서 어떤 작업을 진행할 수 있을 것이다. 대개 Result 객체는 공유 객체가 되어 두 개 이상의 스레드 작업을 취합할 목적으로 이용된다.
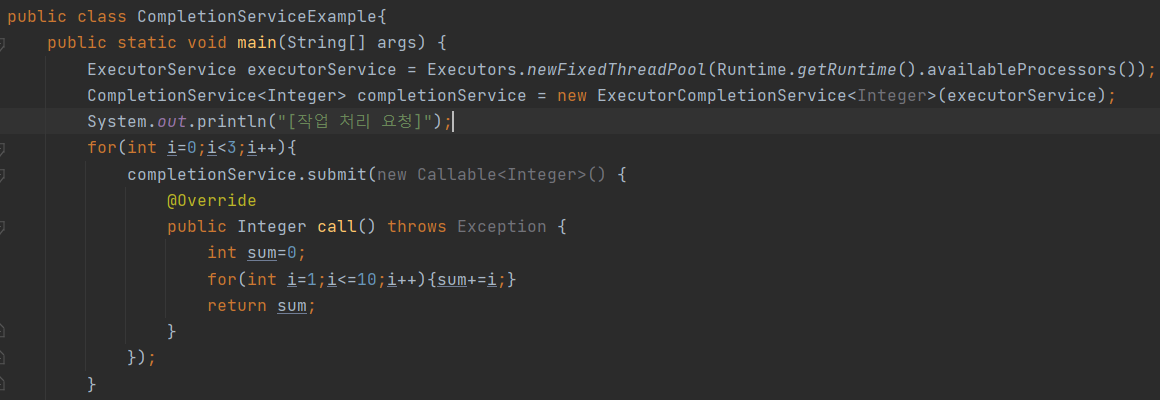
4-6) 작업 완료 순으로 통보
- 작업 요청 순서대로 작업 처리가 완료되는 것은 아니다. 작업의 양과 스레드 스케쥴링에 따라서 먼저 요청한 작업이 나중에 완료되는 경우도 발생한다.
- 여러 개의 작업들이 순차적으로 처리될 필요성이 없고, 처리 결과도 순차적으로 이용할 필요가 없다면 작업 처리가 완료된 것부터 결과를 얻어 이용하면 된다.
- 스레드풀에서 작업 처리가 완료된 것만 통보받는 방법이 있는데, CompletionService를 이용하는 것이다.
- CompletionService는 처리 완료된 작업을 가져오는 poll()과 take() 메소드를 제공한다.
-


4-7) 콜백 방식의 작업 완료 통보
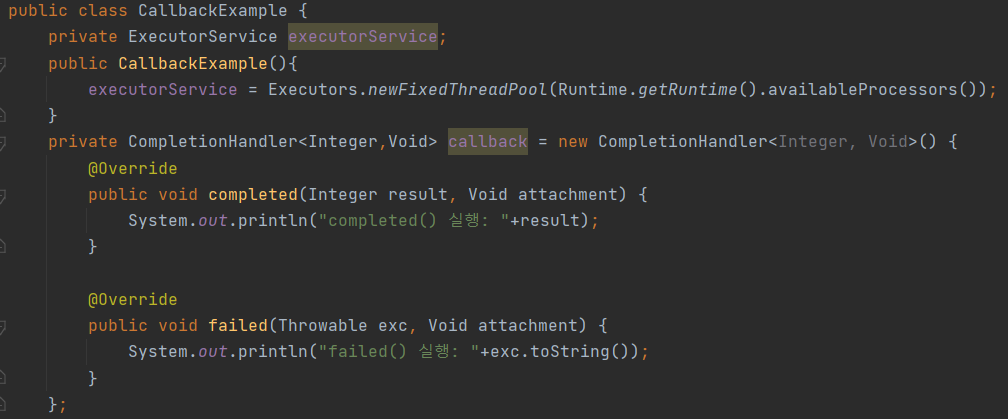
- 콜백이란, 애플리케이션이 스레드에게 작업 처리를 요청한 후, 스레드가 작업을 완료하면 특정 메소드를 자동 실행하는 방식이다. 이때 자동 실행되는 메소드를 콜백 메소드라고 한다.
- 블로킹 방식 vs 콜백 방식
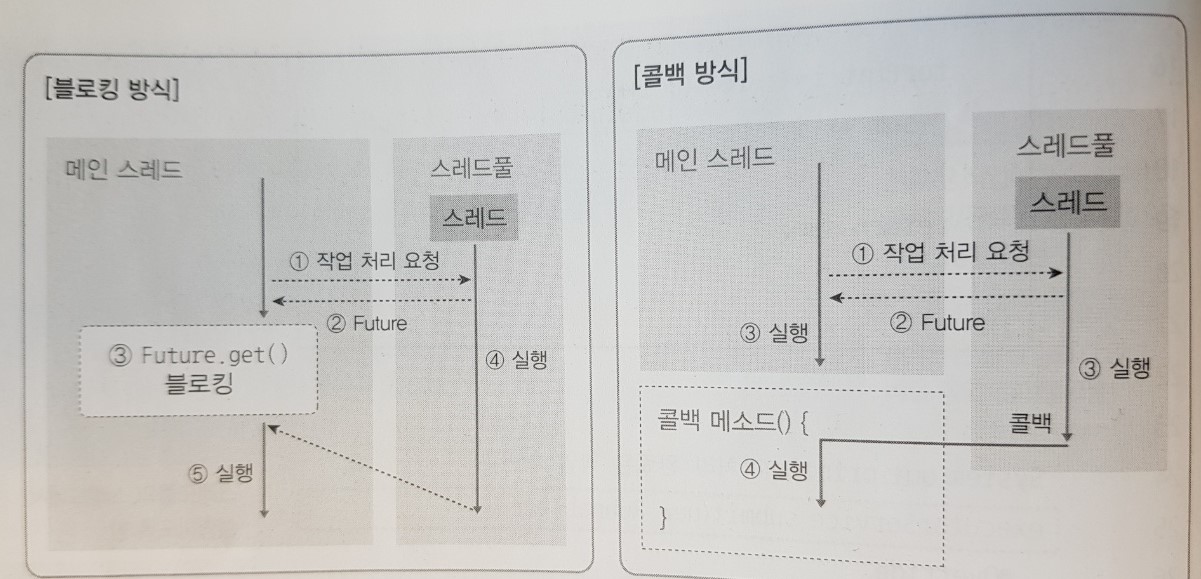
- 블로킹 방식은 작업 처리를 요청한 후 작업이 완료될 때까지 블로킹되지만, 콜백 방식은 작업 처리를 요청한 후 결과를 기다릴 필요가 없어 다른 기능을 수행할 수 있다.
- 그 이유는 작업 처리가 완료되면 자동적으로 콜백 메소드가 실행되어 결과를 알 수 있기 때문이다.


'JAVA > 문법' 카테고리의 다른 글
| [Java/문법] 중첩 클래스와 중첩 인터페이스 (0) | 2022.01.14 |
|---|---|
| [Java/문법] 인터페이스 (0) | 2022.01.14 |
| [Java/문법] 스레드-1 (0) | 2022.01.04 |
| [Java/문법] 입출력(I/O) (0) | 2022.01.04 |
| [Java/문법] 클래스 (0) | 2022.01.03 |



